Integrating SAP HANA 2.0 with Big Data Hadoop Ecosystems
Category: SAP HANA Posted:Apr 03, 2018 By: Ashley Morrison Digital transformation, artificial intelligence and data science are the latest booming fields and all this driving force in the tech space is due to the evolution of Big Data. SAP has been a constant partner in Big Data analytics stored in Hadoop and remains the top player among data management solutions over the past decade. Vora is an initial version of SAP data management solutions which is basically a query engine backed by SAP in-memory capabilities and attached to plug-in using spark execution framework and helps one to combine Big Data with enterprise data and bring results in a fast and simple manner.
Digital transformation, artificial intelligence and data science are the latest booming fields and all this driving force in the tech space is due to the evolution of Big Data. SAP has been a constant partner in Big Data analytics stored in Hadoop and remains the top player among data management solutions over the past decade. Vora is an initial version of SAP data management solutions which is basically a query engine backed by SAP in-memory capabilities and attached to plug-in using spark execution framework and helps one to combine Big Data with enterprise data and bring results in a fast and simple manner.
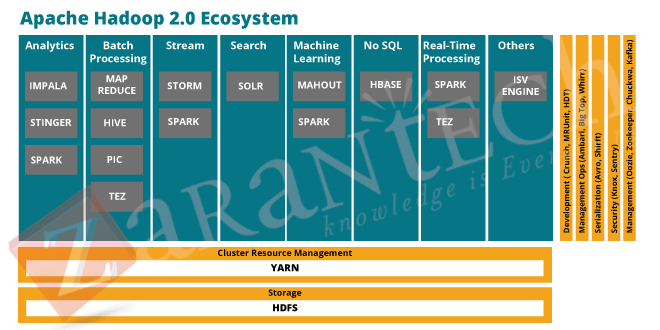
Big Data technology can be quite intimidating to any technologically challenged professionals, but it can be thought of an umbrella held up with strings of many technologies which helps one maintain data and process it by gathering and organizing data in large context.
The term Big Data can be immensely intimidating for any business holder and being in large quantity can be useful to manipulate any query and generate high profits. Sometimes Big Data be in any format, whether its structured or unstructured, which if correctly analyzed and utilized can be used to generate immense profits and strong business moves and is destined to change the business is operated and run.
Learn SAP HANA 2.0 from Industry Experts
What exactly is Big Data?
The very question one may have about generation of large data, but the very source of such Big Data is social media and everyday technologies we use in our everyday life. Each and every technology we use in our day to day life being online generate vast amounts of data. In today’s era the things we are doing, the way we are doing is all important to massive enterprises to understand the human brain and target behavioral patterns to earn more profits through process optimization.
Every enterprise and organizational unit has resorted to use the Big Data to make critical decisions. SAP on-premise and on-demand solutions, especially HANA platform will need closer integration with the Hadoop ecosystem.
These data sets can be characterized in their volume, variety and velocity. These datasets certainly have attributes higher than traditional data sets. These data sets present unique solutions including security of data, including storage, search, processing, generating query, visualizing and updating of data.
Hadoop Big Data solutions
Hadoop is an open data software framework created to distribute massive chunks of data while processing Big Data on large clusters.
Hadoop operates using a divide and conquer strategy, whereas Big Data results are broken into small chunks huge and processed and stored with the final results being assimilated again. The main benefits that Hadoop system provides is that it taps into in-memory benefits for processing and Hadoop’s capability to cost effectively store large amount of data while processing of data in structured as well as unstructured loops which brings out immense possibilities’ of treat business. The other benefits that user can extract are simple databases store large data storage capacity of SAP systems for retaining large data in great volumes and infrequently used. The flexible data store to enhance capabilities to store persistence layer of SAP systems and provide efficient storage of semi structured and unstructured data. The massive data engine and search engine are backed only because of high in-memory storage capabilities of SAP HANA 2.0
Hadoop’s Java based software library provides utilities for parallel data storage and processing aligned with the clusters of data. In the general sense Hadoop is considered as the loop of which consists of open wide range of apache pen source and commercial tools that are based on core software library.
Hadoop solutions are one of the prominent data solutions that provide data structuring in its SAP HANA 2.0 version in a very smooth manner. Hadoop ecosystems are considered as the best storage systems and data storage which are using native operating files over enlarged cluster of nodes. HDFS can provide support for any type of data and provides high degree of fault tolerance by replicating files along multiple nodes.
Hadoop YARN and Hadoop COMMON provide foundational framework for resource management off cluster data. Hadoop MapReduce is a framework for development and execution of distributed data processing applications across multiple nodes. Whereas spark is an alternative data processing framework to work on data flow graphs.
Hadoop MapReduce provides a framework for the development and processing of data depends upon data processing and applications. HDFS datasets can be run very efficiently alongside Hadoop MapReduce vastly focused on data cues and its processing. The Hadoop ecosystem consists of variety of open source and vendor application with complementing and overlapping and similar capabilities and properties’ with different architecture and structured approach.
Integrating SAP solutions and Hadoop
SAP HANA can leverage strong data function along with Hadoop without copying important data to HANA. The most fascinating aspect of integrating SAP HANA 2.0 with Hadoop systems easily using data federation and tools such apache spark as remote access to data systems with many other systems such as SAP IQ, SAP ASE, Metadata, MS SQL, IBM DB2, IBM notes and oracle.
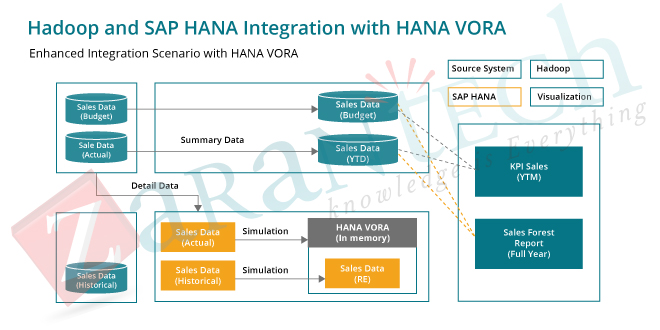
One can easily leverage any amount of data with any time along with in-memory system of SAP HANA 2.0. The collaboration of Hadoop with SAP HANA 2.0 can be easily done with its distributed storage framework and typically can be deployed any amount of data with cluster consisting of several thousand independent machines that performs task within stipulated time, with each cluster involved in processing and storage of data.
Each data cluster can be either bare metal commodity server or any virtual machine . The size of cluster depends upon the requirement of company operation and their business sizes, some choose greater number of smaller size cluster but many can choose various small clusters of large size. HDFS data in Hadoop system plays an important role in fault tolerance and performance with multiple nodes. One of the important aspect that an important role to have nodes storage, nodes are divided basically other types and their role performing in the operation of Hadoop and SAP HANA 2.0 systems.
The most prominent thing that separates Hadoop from its components is the four components that are useful into its smooth running, the very initial era the entry level servers, secondly the HDFS file distribution system that spreads data evenly across the cluster evenly by redundant way. Third the most important factor called as YARN which handles workload distribution along the resources and fourth being the most important aspect which is MAP reduces enabling top Hadoop cluster. This clusters are prepared with great optimization considering all graph processing, along with machine learning and literature combines. The most common MapReduce example is that about its word count program. This is one of the sample programs that are shipped along with installing Hadoop.
Vora can access data of HANA through SPARK SQL. Fault tolerance one of the aspect that is replicated with HDFS data in Hadoop system. The Hadoop system is mostly deployed with along with several clusters which are replicated with data processing, some organization tends to have larger cluster that have been replicated to adjust along with its data storage and processing of data. Nodes are basically separated along with their type and role. The role of master nodes is to provide key central coordination services for distributed storage and processing, while worker nodes are involved with actual storage and processing.
The main components of basic Hadoop cluster are named node, data node, resource manager and node manager. The role of name nodes coordinates data storage with data nodes while role of resource manager node coordinates with data processing on node manager within the cluster. The main components among cluster are workers which can be added to cluster nodes. They mainly perform both roles of data node and node manager wheeze as there could be data nodes and compute only nodes as well. More cluster nodes can be added by deployment of various other components ranging from Hadoop ecosystems which bring sore services in the loop and more types of nodes can came along to play subsequent roles. The process of node assignment for various services of an application is dependent on performing task schedules of that application.
Simplification is a benefit that can be more directly linked with SAP HANA and Hadoop integration. This is particularly important since it reduces issues with settlement and in its place promotes one source of truth. FI and CO related dealings are saved as a single line item, this improves the reliability of the data across functions. SAP Hadoop brings vital simplicity to the management and administration of the complete IT landscape, and attached to the cloud adoption potential that it brings to the front, hardware and network resources have never been so central.
Register for the Live webinar on SAP HANA 2.0 by Industry Experts
The selection of integrated SAP Hadoop is a cost friendly option when you think the fact that you are able to join all the analytical and transactional capability of diverse systems into a single source of truth which drives sensitive and down to earth business decision making. The benefits of Cross-functional transparency come as an advantage of SAP Hadoop so it enables a reliable and dependable workflow. The potential to access information on various system areas and work cross-functionally enables further real-time insights and analytics into data across the organization
SAP Hadoop is one of the top optimized products from SAP that is driving cloud adoption by businesses. The cloud presence offers a platform for different software suppliers to offer magnificent products that sums up and extend the ability of HANA combined with Hadoop. Enterprise decisions cannot be made lightly among traditional SAP solutions as SAP comes from the leading ground of conducting business in today’s fundamentally challenging and complex business landscapes along with its Hadoop ecosystem.
The user interface is completely driven by SAP Hadoop, which is SAP HANA backed, therefore it makes user friendly version of real time business insight and data on any device brings it a creditable business advantage over anytime and anywhere. The use of Hadoop as new, leads to improved productivity. The advantage available across SAP HDFS and SAP HANA 2.0 provides several transactions using a single app and transactions are processed with fewer clicks and screen fill out can be customized to get enhanced user experience.
S/4 HANA 2.0 is SAP HANA’s flagship program. The speed of HANA 2.0 lets achieve maximum benefits with its data, as for instance, finance team can run multiple jobs without waiting for one to complete. The jobs can be run as many times to get refined results. HANA 2.0 allows one to experience top notch performance as complex and time driven business such as execution, reporting, real time planning and various analytics of live data as well as improved forecasting and prompt period closing. The main benefit of it is to provide customer centric application.
Conclusion
The operation monitoring cost can be greatly reduced by usage of SAP HANA 2.0. This helps in avoiding data delays which can question organizations data reliability. Through SAP HANA 2.0 business tools organization can report directly from their traditional databases. SAP HANA 2.0 helps organizations to make quicker decisions through enhanced visibility. Users in general can create as necessary queries to extract any data as necessary which is limited for non-HANA database users.
The use of HDFS/ Hadoop Data File System has changed the business view to modern design of comprehensively redesigned user experience. The qualities that make user interface best among all are highly responsive features, which are personalized and fundamentally simple, which ultimately leads to role based user experience and along with best user experience across cross platform devices.
The most important factor that most of users are unaware of modern product, but it’s not necessary that a product launched today’s is modern in its aspect, but only that product is modern that serves the most future requirement of the user which has been trying to do in SAP HANA 2.0. In many instances there were many ECC applications, but what SAP HANA 2.0 and Hadoop aims at providing is data accessibility, context and speed which many applications failed to achieve it. SAP HANA Hadoop is the only system where no one is compelled to upgrade to an upward version or instances where they might migrate certain amounts of data as it keeps most of its updates optional to its customers.
One of the most fascinating features for most of its users is its innovative application. This is as SAP applications are developed keeping in mind about the future. Also significant is SAP HANA Hadoop’s ability to synchronize and scale with the latest users, technology and demand. Today is the era where technology is changing to an unimaginable speed where most firms are evolving constantly, whereas SAP HANA 2.0 provides enterprises with such a technologically advanced platform that enables firms to match up with the latest technology.
SAP follows a more of a holistic approach to develop a set of financial accounting and management solution, calculating and spanning financial analysis and also planning and guiding a firm’s risk and compliance management. The supportive tools of Hadoop even stand for collaborative finance operation, treasury management and even supporting financial close.
Financial planning and analysis are one of the efficient finance functions that can tremendously boost up planning cycles and so variably do boost the profitability of finance functions. Data replication issues can be easily countered by planners as they can access real-time master data with accruals very efficiently in integrated Hadoop system. Clients can easily link up their planning and utilize real time operational data that can be helpful in removing possible time lags and un-necessary data.
Financial analysis can be done on the go with desired levels of granularity using an individual table in-memory. Updates, development and reporting can be inseparable part of organizations whole financial planning lifecycle. The success of any client lays in its adoption of a system such as SAP HANA 2.0 and Hadoop system.
Stay tuned with us for more such posts related to SAP HANA 2.0, Big Data Hadoop System!! You can also visit our website. Zarantech will help you skyrocket your career with self-paced online training on various aspects of SAP , Workday related topics, feel free to visit our course page.





 99999999 (Toll Free)
99999999 (Toll Free)  +91 9999999
+91 9999999