Python Basics for Data Science
Category: Data Science, Python, Python for Data Science Training Posted:Nov 26, 2019 By: Serena Josh
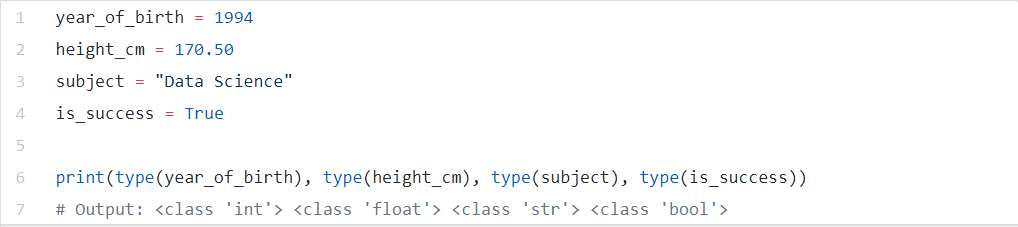
In Python for Data Science, we have numerous data types. The most well-known ones are float (floating point), int (integer), str (string), bool (Boolean), list, and dict (dictionary).
- float – utilized for genuine(real) numbers.
- int – utilized for integers.
- str – utilized for writings. We can characterize strings utilizing single quotes ‘value’, twofold quotes “value”, or triple quotes “””value”””. The triple cited strings can be on different lines, the new lines will be remembered for the estimation of the variable. They’re likewise utilized for composing capacity documentation.
- bool – utilized for truthy values. Helpful to play out a separating activity on the information/data.
- list – used to store collection values.
- dict – used to store key-esteem sets.
We can utilize the type (variable_name) capacity to check the kind of a particular variable. Operators in Python carry on distinctively relying upon the variable’s sort and there are diverse worked in techniques for everyone.
Here we can take a glance at certain models with making a floating-point, integers, strings, and booleans in Python.
Python Lists:
The Python list is an essential succession type. We can utilize this sort to store an assortment of qualities. One rundown can contain estimations of any sort. It is conceivable that one list contains another settled list for its qualities. It’s not usually utilized, yet you can have a rundown with a mix of Python types. You can make another one utilizing square brackets this way:

Subsetting Lists:
You can utilize indexes to get components or components from the list. In Python, the indexes start from 0. Subsequently, the principal component in the list will have a file 0. We can likewise utilize negative indexes to get to components. The last component in the list will have an index- 1, the one preceding the last one will have an index – 2, etc. We have added something many refer to as a list slicing in Python which can be utilized to get various components from a list. We can utilize it like this: “sliceable[start_index:end_index:step]”.
- The start_index is the starting index of the slice, the component at this index will be incorporated to the outcome, the default esteem is 0.
- The end_index is the end index of the slice, the component at this index won’t be incorporated to the outcome, the default worth will be the length of the list. Additionally, the default worth can be – length of the list -1 if the progression is negative. On the off chance that you skirt this, you will get every one of the components from the beginning index as far as possible.
- The step is the sum by which the index increases, the default esteem/value is 1. In the event that we set a negative value for the progression, we’ll go in reverse.

List Manipulation :
- We can add components or components to a list utilizing the append technique or by utilizing the plus operator. In case you’re utilizing the plus operator on two records, Python will give another list of the substance of the two lists.
- We can change components or components to list utilizing similar square sections that we previously utilized for indexing and list slicing.
- We can erase a component from a list with the remove(value)technique. This strategy will erase the primary component of the list with the passed value.

It’s essential to see how the list works in the background in Python. At the point when you make another rundown(list) my_list you’re putting away the list in your PC memory, and the location of that list is put away in the my_list variable. The variable my_list doesn’t contain the components of the list. It contains a reference to the list. On the off chance that we duplicate a list with the equivalent sign just like this my_list_copy = my_list, you’ll have the reference replicated in the my_list_copy variable rather than the list esteems. Along these lines, in the event that you need to duplicate the genuine qualities, you can utilize the list(my_list)function or slicing [:].

Python Dictionaries :
The word references are utilized to store the key-value pairs. They are useful when you need your qualities to be indexed by unique keys. In Python, you can make a dictionary utilizing curly braces. Likewise, keys and values are isolated by a colon. On the off chance that we need to get the value for a given key, we can treat it so harshly as that:
our_dict[key]
Dictionaries vs Lists:
How about we see a model and look at the list versus dictionaries. Envision that we have a few motion pictures and you need to store the appraisals for them. Likewise, we need to get to the rating for a film exceptionally quick by having the motion picture name. We can do this by utilizing two lists or one-word dictionaries. In examples the movies.index(“Ex Machina”)code restores the index for the “Ex Machina” film.


For this situation, the utilization of a dictionary is an increasingly instinctive and advantageous approach to speak to the appraisals.
Dictionaries Operations:
We can include, update, and erase data from our dictionaries. At the point when we need to include or refresh the data, we can essentially utilize this code our_dict[key] = value. At the point when we need to erase a key-value pair, we do this like del(our_dict[key]).

We can likewise check if a given key is in our dictionaries like that: “key in our_dict”.

Functions:
A function is a bit of a reusable code solving a particular task. We can compose our capacities utilizing the def keyword like that:

Be that as it may, there are many built-in in Python like max(iterable max(iterable [, key]), , min(iterable [, key]), type(object), round(number [, ndigits]), and so forth. Along these lines, much of the time when we need a function that understands a given undertaking, we can inquire about a built-in function that tackles this errand or a Python package for that.
The greater part of the function takes some input and returns some output. These functions have contentions, and Python coordinates the past input to a function call to the contentions. In the event that square brackets encompass a contention, it’s optional.
We can utilize the function help([object])or ?function_name to see the documentation of any function. In case we’re utilizing Jupyter Notebook, the help function will show us the documentation in the present cell, while the subsequent choice will show us the documentation in the pager.
Methods(Strategies):
We’ve seen that we have strings, float, integers, booleans, and so forth in Python. Every last one of these information structures is an object. A strategy is a function that is accessible for a given item relying upon the object’s type. Along these lines, each object has a particular type and a lot of techniques relying upon this type.

Objects with various types can have strategies with a similar name. Contingent upon the object types, techniques have distinctive conduct.

A few techniques can change the object they are approached. For instance, the append() technique approached the list type.
Packages:
A module is a record containing Python definitions and proclamations. Modules determine capacities, strategies and new Python types that tackled specific issues.
A package is an assortment of modules in directories. There are numerous accessible packege for Python covering various issues. For instance, “NumPy”, “matplotlib”, “seaborn”, and “scikit-learn” are acclaimed data science package.
- “NumPy” is utilized for effectively working with Arrays’,
- “matplotlib” and “seaborn” are well-known libraries utilized for data representation
- “scikit-learn” is a ground-breaking library for machine learning
There are a few packages accessible in Python naturally, yet there are likewise such a significant number of bundles that we need and that we don’t have as a matter of course. In the event that we need to utilize some bundle, we must have it install as of now or simply install it utilizing pip (package maintenance system for Python).
In any case, there is additionally something many refer to as “Anaconda”.
Anaconda Distribution is a free, simple to install package manager, environment manager, and Python distribution with an assortment of 1,000+ open-source bundles(packages) with free network support.
Thus, on the off chance that you would prefer not to introduce numerous packages, I’ll prescribe you to utilize the “Anaconda”. There are such a significant number of helpful bundles in this distribution.
Import Statements:
When you have installed the required packages, you can import them into your Python documents/files. We can import whole packages submodules from it. Additionally, we can include an alias for a package. We can see the various methods for import statements from the given examples.




We can likewise accomplish something like this from numpy import*. The reference mark (asterisks) image here intends to import everything from that module. This import statement makes references in the current namespace to every single open item characterized by the numpy module. As it were, we can simply utilize every accessible capacity from numpy just with their names without prefix. For instance, presently we can utilize the NumPy’sabsolute function like that absolute()rather than numpy.absolute()
In any case, I’m not prescribing you to utilize that in light of the fact that:
- In the event that we import all functions from certain modules like that, the current namespace will be loaded up with such a significant number of function and on the off chance that somebody takes a gander at our code, the person can get confused from which package is a particular capacity.
- On the off chance that two modules have a function with a similar name, the subsequent import will abrogate the function of the first.
NumPy:
NumPy is an essential package for scientific computing with Python. It’s quick and simple to utilize. This package encourages us to make estimations component-wise.
The normal Python list doesn’t have the foggiest idea of how to do tasks component-wise. Obviously, we can utilize Python lists, yet they’re moderate, and we need more code to accomplish a needed outcome. A superior choice much of the time is to utilize NumPy.
Dissimilar to the normal Python list, the NumPy array consistently has one single type. On the off chance that we pass an array with various sorts to the np.array(), we can pick the needed type utilizing the parameter dtype. On the off chance that this parameter isn’t given, at that point, the type will be resolved as the minimum kind required to hold the objects.
np.array([False, 42, "Data Science"]) # array(["False", "42", "Data Science"], dtype="<U12") np.array([False, 42], dtype = int) # array([ 0, 42]) np.array([False, 42, 53.99], dtype = float) # array([ 0. , 42. , 53.99]) # Invalid converting np.array([False, 42, "Data Science"], dtype = float) # could not convert string to float: 'Data Science'
NumPy array accompanies his very own properties and techniques. Remember that the operator in Python acts distinctively on the various data types? All things considered, in NumPy the operator carries on component-wise.
np.array([37, 48, 50]) + 1 # array([38, 49, 51]) np.array([20, 30, 40]) * 2 # array([40, 60, 80]) np.array([42, 10, 60]) / 2 # array([ 21., 5., 30.]) np.array([1, 2, 3]) * np.array([10, 20, 30]) # array([10, 40, 90]) np.array([1, 2, 3]) - np.array([10, 20, 30]) # array([ -9, -18, -27])
On the off chance that we check the kind of a NumPy array the outcome will be numpy.ndarray. Ndarray implies an n-dimensional array. In the models above we utilized 1-dimensional array, however, nothing can stop us to make 2, 3, 4 or more dimensional array. We can do subsetting on an array autonomously of that how much measurements this array has. I’ll give you a few models with a 2-dimensional array.

On the off chance that we need to perceive what number of dimensional is our array and what number of components have each measurement, we can utilize the shape property. For a 2-dimensional array, the primary component of the tuple will be the number of rows and the second the quantity of the columns.

Essential Statistics :
The initial step of breaking down data is to get acquainted with the data. NumPy has a lot of strategies that help us to do that. We’ll see some fundamental strategies to make statics on our data.
- np.mean()- returns the arithmetic mean (the sum of the components divided by the length of the components).
- np.median()- returns the median (the center value of an arranged copy of the passed array, if the length of the array is even – the normal of the two middle values will be computed)
- np.corrcoef()- returns a correlation matrix. This function is helpful when we need to check whether there is a connection between’s two factors in our dataset or with different words, between two arrays with a similar length.
- np.std()- returns a standard deviation

From the above examples, we can see that there is a high connection between’s the long stretches of learning and the evaluation.
Likewise, we can see that:
- the mean for the learning hours is 4.6
- the middle for the learning hours is 4.0
- the standard deviation for the learning hours is 3.2
NumPy likewise has some essential capacities like np.sort() and np.sum()which exists in the basic Python list, as well. A significant note here is that NumPy implements a single type in an array and this paces up the calculations.





 99999999 (Toll Free)
99999999 (Toll Free)  +91 9999999
+91 9999999